If you include page number and update the url param correctly, back should work as expected to go to previous page (if navigated from). It would be unexpected to go to page 3 from 4, if I'd opened 4 directly or from 1.
I've started adjusting the url (mainly for browser users) so that you have a url to jump into if you want to return to a certain page.
Also, back button does work to get you out of the text and back to the main list of texts, but I'm having trouble (without having to change a ton of other stuff) allowing the back button to just go back one page (if you are looking at a multi-page text).
For the suggested page tracking (if you end up working on it), could just be a return to (ex) Page 4 under/next to the doc title on the main list
It's not that easy, unfortunately. renshuu has a home-grown SPA (single-page-app) implementation which works, but is not what you'd call *thoroughly robust". So moving back is not just loading the pages (which could be done, if the SPA was not in place, but a ton of JS manipulating the browser history and cache for various speed benefits.
So while I'm pretty confident that it can be done, I'm not quite sure how to handle it.
I'll add some technical notes at the bottom.
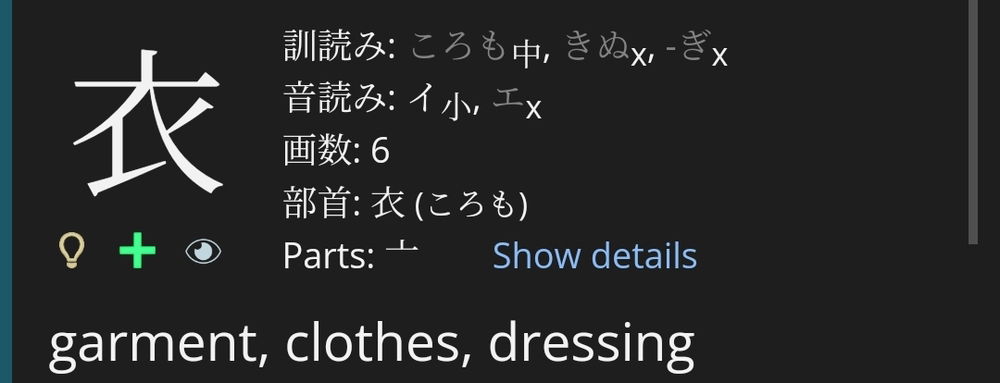
As to the missing lightbulb - I'll consider adding that later, but not at the moment. That term list is the same as the term list everywhere else, so I'd need to make special options there to handle the extra icons.
Technical stuff.
So, for most devices, renshuu holds 3 or 4 of the last pages/modals (modals = term lists, grammar pages, and now, text analyzer reader) in a small cache. When a new page is loaded, the url is rewritten by JS, and then the page is loaded via ajax and put in place. Press back, and it rolls the window's history back one, which triggers the cache system to not actually reload the previous page, but to toss the cached page back up (unless the cache runs out).
Here's the problem: consider a 5 page reader.
When you open it, the page's url will be /text/text_id/pg_number, or as an example, /text/1000/0
If you go the next page, it is /text/1000/1, /text/1000/2, and so on.
If you were to use the back button, this would normally work fine - it would grab the last cached copy, which is the previous page. Easy!
However, let's say the cache has three pages on it:
/text/1000/0
/text/1000/1
/text/1000/2
If you then press the x in the top right, you'd want to clear out those 3 entries, and return to whatever was before it (the main TA page).
I originally tried something like this: (pseudo-code)
while( last cache entry is a reader page ) {
//add code to prevent the page from actually showing the cache for all the intermediary pages
window.location.back();
}
You may think this would work, as it would clean off all the cached pages, and clear the urls out of the browser's history (which you cannot do manually - you can either replace the current one, or add onto it)
However, window.location.back() is asynchronous! AHHHH. So that loop would run 1000 times before the 1st one finishes, and the browser would (and did) crash.
The main issue with all of this is that you cannot easily manipulate the browser history when going backwards - you must use the window.location.back().
Tricky.