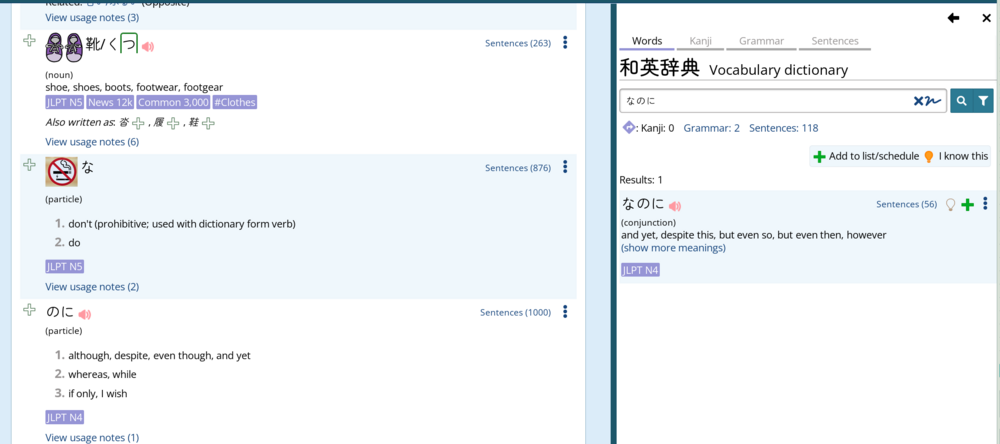
For some reason, なのに is parsed as な+のに in Reading Buddy. In the regular dictionary, it gives expected results. In the screenshot, Reading Buddy is on the left, dictionary is on the right.
Sentence is used in this example is
これは新しい靴なのにもう修理する必要がある
I would expect that なのに can be looked up in the dictionary, but maybe な gets translated first since it has its own entry?
As I recall, Michael is using a greedy algorithm, so it makes these kinds of mistakes fairly often. There’s no way to fix it without bringing in a lot of statistics or AI, and even then it would guess wrong occasionally. So we have to work around it.
That one is actually not that particular parser, but the one used in the Text Analyzer - it's a bit more complex, but I basically take what comes out of that and format it for renshuu's usage.
The above results may not be desired in some cases, but it's working regularly.
If you were to look up 靴なのに in the dictionary, you'd get the same result as the RB.
What's happening in the dictionary (both, really), is that first it'll see if there is a single word that matches what you are searching for. So if you search for なのに, it'll look for and find the term, and return that.
If there are no results, it says "hey, maybe this is a phrase or sentence, let's try breaking it up). It sends it to a micro-version of the text analyzer, which says "I think it's 靴 / な / のに", and then each of those words are returned. Same result on https://ichi.moe/cl/qr/?q=%E9%..., which uses the same underlying parser as renshuu.
The only "fix" is to say "if the TA sees な and のに, group them", but I cannot say with certainty if there are times when that would not be desirable.